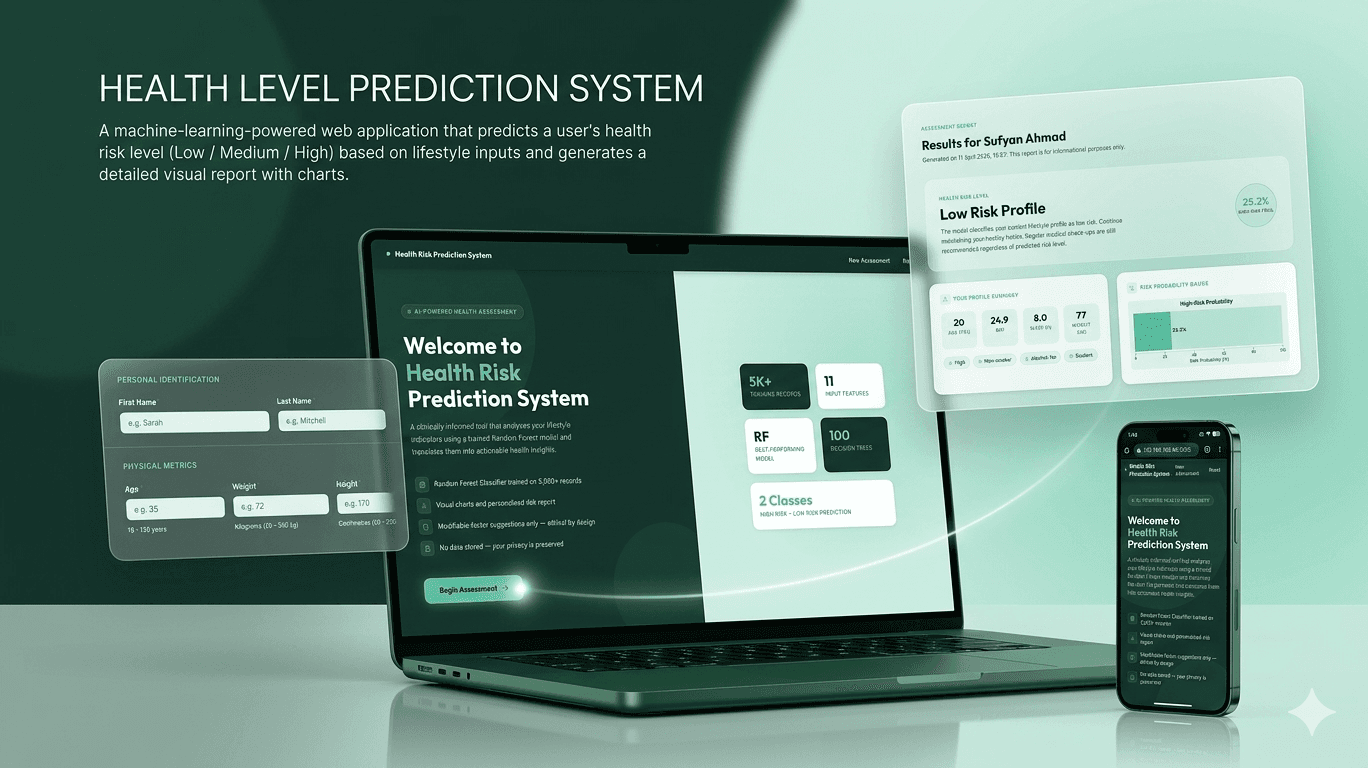
Health Level Prediction System
Executive Summary
The Health Level Prediction System was engineered to provide immediate, data-driven health risk assessments.
Technical Context
The Build Logic
Executive Summary
The Health Level Prediction System was engineered to provide immediate, data-driven health risk assessments. By processing a complex array of daily lifestyle inputs—such as age, BMI, sleep duration, exercise routines, smoking habits, and profession—the system accurately predicts a user's health risk tier (Low, Medium, or High).
The objective was to build a highly responsive, machine-learning-powered web application capable of:
- Preprocessing user lifestyle data in real-time
- Running rapid ML inference to determine risk categorization
- Generating granular visual diagnostic reports
- Maintaining a stateless web architecture for seamless user flow
The system utilizes a Scikit-Learn Random Forest Classifier trained on a large-scale synthetic dataset, delivering personalized health insights instantly without requiring clinical intervention.
The Problem
Traditional preliminary health assessments suffer from several structural limitations:
- They often rely on isolated metrics (like only BMI or only age) rather than holistic lifestyle data.
- Users must navigate complex, multi-step clinical portals to get basic preventative insights.
- Static web forms provide generic text feedback rather than dynamic, personalized visual analytics.
- Storing personal health inputs often introduces severe database privacy concerns and compliance overhead.
There was a clear need for a fast, stateless diagnostic tool that could leverage heavy data science models while delivering instantaneous, easily digestible graphical reports directly to the user.
The Solution
The Health Level Prediction System integrates:
- A pre-trained Random Forest Classifier capable of handling complex categorical and numerical inputs.
- A dynamic, multi-page Flask web interface that uses session states to manage user data securely.
- Real-time Matplotlib generation to create visual risk gauges and feature breakdown charts.
The result is a highly contextual ML system that delivers:
- An accurate Low/Medium/High risk classification
- Inline graphical reports comparing user metrics against baseline health standards
- A completely stateless backend where no personal health data is persistently saved to a database, ensuring absolute privacy and high performance.
System Architecture
-
Data & Preprocessing Layer
Data ingested from a synthetic lifestyle dataset (~270K rows).
Extensive preprocessing utilizingStandardScalerfor numerical normalization.
Binary mapping viaLabelEncoderand categorical mapping via One-Hot Encoding for fields like profession and exercise type. -
Intelligence Layer
The core engine is aRandomForestClassifieroptimized for multi-class prediction.
Models and scalers are serialized and exported viajoblibfor rapid memory loading. -
Visualization Layer
Matplotlib dynamically generates comparison bars and gauge charts.
Charts are converted directly into base64-encoded PNG strings to be served inline. -
Application Layer
Python/Flask backend handling orchestration and routing.
Jinja2 HTML templates with custom CSS rendering the frontend.
Flasksessionhandles state transfer between the form submission and the final results page.
Engineering Decisions
Why Flask Sessions Over a Database?
To maintain a strictly stateless application. By utilizing secure cookies/sessions, the app avoids the overhead, latency, and security risks of permanently writing transient medical data to a persistent database.
Why Base64 Inline Image Encoding?
Generating physical image files for thousands of concurrent users would create massive I/O bottlenecks and require complex cleanup scripts. Encoding plots to Base64 strings directly in RAM and passing them to Jinja2 ensures a clean, memory-efficient pipeline.
Why Random Forest?
It provides excellent robustness against overfitting on diverse categorical lifestyle data and handles the non-linear relationships between health factors seamlessly.
Performance Metrics
Model training capability: handles ~270K rows efficiently.
Inference latency: < 100 milliseconds per prediction.
Visual report generation: < 1 second for fully rendered Matplotlib inline charts.
Memory overhead: minimized due to lack of persistent I/O file writing.
Scalability Strategy
Joblib serialization allows rapid swapping or upgrading of the ML models without altering the backend code.
The completely stateless Flask architecture means the application can be seamlessly horizontally scaled across multiple load-balanced web servers.
Potential future integration with automated API endpoints for external B2B health triage.
Outcome
The Health Level Prediction System demonstrates how complex Scikit-Learn pipelines can be effectively deployed into consumer-facing web applications.
It is architected as a highly efficient, privacy-first predictive tool that prioritizes immediate visual feedback over bloated backend data retention.
System Visuals
Scalability is the only standard
Ready to integrate these levels of intelligence and performance into your own ecosystem?